Update to this. UK government have finally put this out. Finally some decent stats!
Also, here's the mobile version, but the other one is better.

Update to this. UK government have finally put this out. Finally some decent stats!
Also, here's the mobile version, but the other one is better.
After reading through my coronavirus post, my friend Joe had stated that I should have had more flow diagrams in it.
So Joe, this diagram is especially for you:

So this virus outbreak thing is interesting isn't it?
As a mathematician-in-training, what I'm finding more interesting is the lack of good statistics on what's happening. The UK government were initially publishing new infections within England and in the whole of the UK. In addition, they were publishing the total UK infected, and total UK deaths. They stopped reporting anything on March 5th.
Though as well as keeping track of government announcements, I've also been keeping record of daily updates that the World Health Organisation (WHO) have been making.
Here's a link to their European map.
Here's a link to their global map.
On a daily basis, I've been recording UK totals from their site. You can see them graphed below:
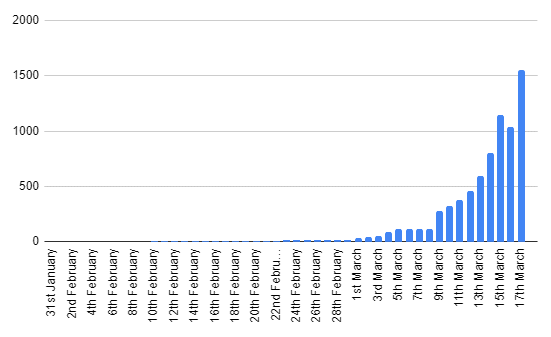
You can't see it, but the values for the first 9 days are just two people.
Though see how there's a dip on March 16th? How could there possibly be a dip in cases for one day by over 100 people? It seems even the pros can get their numbers wrong. Bad work, WHO. 🙁
Also, you'll notice from around March 5th to March 8th, it goes flat. These are days on which I didn't check the figures.
From these total cases per day, I've calculated new cases per day.
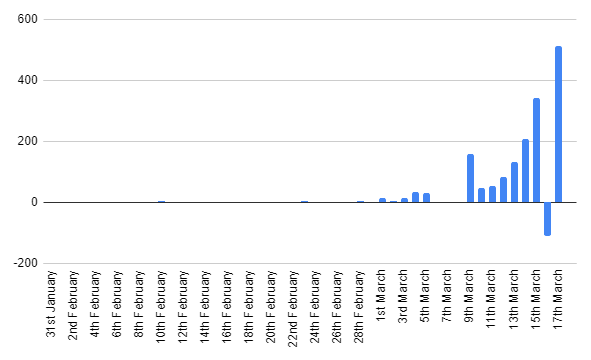
See that negative number of new cases on March 16th? Insert eyeroll emoji.
There's also a spike on March 9th, this is just total new cases from March 5th to March 9th. -catching up from when I didn't check on the totals on these days.
But as you can see, as predicted, this initial growth is basically exponential. Fairly typical for an epidemic apparently.
So the big question is... what next?! -and here's where my mathematics and statistics study comes in handy... I've recently finished a section on epidemics! What better time to apply some of my learning!
First off, it's worth mentioning that all the epidemic modelling I've learned about assumes homogeneous mixing. This is the kind of mixing that occurs in a family home. ie: there's more or less an equal chance of me having contact with one person than there is anyone else. In real life this, of course, isn't true. Living in London, I'm less likely to be in contact with someone in Edinburgh than I am someone I travel with on the London Underground every day. Also important point: homogeneous mixing means no quarantining. So all of the below is essentially average worst-case.
So with the proviso that these results will probably (more than likely) be wildly inaccurate, let's get started! We need a few important numbers, some of which we've already got:

Where:
Which is fine, but how do we know what γ and β are? Well there's a number called R0 ("R-naught") that I've NOT been taught about that represents the contagiousness of a virus. Interestingly, I've found two completely opposed descriptions of this number:
Though we all know how reliable wikipedia is, and I've just found this Stanford paper which supports the towardsdatascience description:

Therefore:

Hooray. Imperial College London seems to estimate the R0 of COVID-19 to be 2.4, so let's run with that.

Once we have all this, we can work out the maximum number of infectives at any one time. ie: the peak of the infection in the population, ymax:

Now we can plug all the numbers in to find ymax! So:

Hence:

Which is 42.5% of the population infected at one time! Ouch! At least you'll know that if we (in our theoretical UK) hit 28 million with no quarantining, we'd be at the peak of the outbreak.
Other sources state that COVID-19 actually has a range of R0 values, 1.4-3.8-ish, so the band of possible outcomes without quarantining is actually quite broad. But from this it's possible to work out a best-case/worse-case comparison:
An R0 of 1.4 would mean a max of 12.2 million (18% of the population), and an R0 of 3.8 would mean a max of 39.4 million (58% of the population) at one time.
The following assumes that the whole debacle is over. Everyone that has caught the virus from it has now recovered. How many people were not affected?
This is found using the following iteration formula:

Initially x_{inf,j} is zero, and you use your result x_{inf,j+1} to calculate x_{inf,j+2}, and so on. This eventually settles down to the number of people not affected!
So using the power of spreadsheets, and not taking up the space here with columns and columns of numbers:
You can imagine that an increase in quarantining means a lower R0. Seems that could have a big effect.
#ImNotAStatisticianButItsStillFunLookingAtNumbers
Two thirds of the way through my assignments!
Again, fairly happy with the mark I received for this, but there were some aspects of this assignment I found challenging, and some where I thought I might've done quite well on, but slipped up in some way.
Let's cover some areas here:
For these questions I had to find a real-world process that could be modelled with the given mathematical objects/processes. Kind of the opposite of a mathematical modelling problem.
I found these tasks really difficult. What I found to be the worst aspect about getting this kind of question wrong is that it's not necessarily my understanding of the mathematical process that's flawed. I feel in each of these cases, I did my best to find a real world example, knowing that the example I gave, itself, was slightly flawed. So despite the fact that I can perfectly explain each mathematical process, I couldn't explain how each could be applied to a real world process so lost marks.
The two models were the Galton-Watson branching process, and the simple random walk (specifically, a particle executing a simple random walk on the line with two absorbing barriers).
The two typical examples that are referred to in my texts are genetics and mutations for the Galton-Watson branching process:
"A mutation is a spontaneous transformation of a particular gene into a different form, and this can occur by chance at any time... The mutant gene becomes the ancestor of a branching process, and geneticists are particularly interested in the probability that the mutation will eventually die out."
For the simple random walk, the example of the "gambler's ruin" was given. Imagine two people with £10 each, each of them betting on an event. If one of the two loses the bet, they give £1 to the other (the random walk on the line). If one of them runs out of money, then they lose (one of the "absorbing barriers" are hit).
In coming up with answers, I could've used Google, but that would've been cheating. However, now I've completed the assignment and received my grade, Google is my best friend in finding suitable answers here...
Seems you can use the Galton-Watson branching process to determine the extinction of a family name, and I found a good example of a random walk with absorbing barriers in this MIT paper, featuring a little flea called Stencil. It discusses the probability of him falling over the Cliff of Doom in front of him, or the Pit of Disaster behind him.
A couple of my answers here and there were classed as being incomplete. Generalising each case:
1)
Upon finding that an answer resembles a certain construction (a probability distribution function, cumulative distribution function or generating function), as well as saying which distribution the function belongs to, you should also explicitly state the variables that appear in it. Even to anyone non-mathematical, it would be obvious to see that the variables in the general case are associated with the specific answer you arrived at. Though for assignments (and exams, presumably) this is not enough. If a general function has variables explicitly state what each one is in your answer.
eg: the p.g.f. of the modified geometric distribution is

If your answer resembles this, say what a, b, c and d are.
In addition, if your answer is a probability (or set thereof), include a statement describing them.
Note that one whole mark can be deducted for an insufficient conclusion (apparently).
2)
Don't forget your definitions.
Specifically:
To calculate the variance of the position of a particle (along the random walk line) after n steps, you can just sum the variances of each step. However this only works because each individual step is independent of the last (one of the properties of the random walk). Due to the fact that I didn't mention this definition of the variance of a particle in a random walk, I lost half a mark. Not massive, but where you can mention a definition, mention it.
I struggled with this, and although I arrived at the correct answer, the method I had used was entirely wrong (and also a little inelegant).
In this question, I covered all routes separately and so had a small handful of different probability calculations. Though when considering potential routes in a Markov chain, you can consider all routes simultaneously by taking advantage of something called an absolute probability (of the Markov chain being in a particular state at a particular time), given an initial distribution. (for my own reference this is covered in Book3, Subsection 11.2, p.87. And the handbook, p.23 item 17).
Does it matter if an arbitrary constant is positive or negative? (my ref: Q6a). I previously thought not. In this instance my constant in an integral calculation absorbed the negative sign that was in front if it. After all, a negative general constant is still a general constant, right? Well I lost half a mark here because of the absorption, and it's not currently clear why. I've asked my tutor, and I'll update it on here once I hear back from him.